
9月になってしまいましたね。今年もあと4ヶ月です。
本日はPythonシリーズです。機械学習を勉強する上で重要になるのがデータを如何にして集めるかということだと思います。
機械学習は大量のデータを使ってモデルに学習をさせるため、必要なデータを十分量集める必要があります。
大量のデータが必要な場合いちいち手作業でデータを集めるの大変だよねー
このデータ収集に便利なのがスクレイピングという手法です。今回はPythonでスクレイピングを勉強してみましたのでご紹介したいと思います。
スクレイピング
スクレイピング(scraping)はウェブサイトから情報を抽出するコンピュータソフトウェア技術のことです。
通常ウェブページからデータを取得する場合は手動でコピーするのは一般的かと思います。少量のデータであればそれで良いかもしれませんが、まあまあのデータ量の場合はめんどくさいですよね。それを自動で行うのがスクレイピングと呼ばれるものです。
scrap(英語)…意味:切れ端,小片,断片。よくスクラップとか呼ばれますよね。
scraping(英語)…意味:こすること、削ること。スクレイピングもこの単語から来ているとのことですが、ウェブページを少しずつ削って情報を収集するといった意味でしょうか。
crawl(英語)…意味:這う,のろのろ走る。クロールはスクレイピングと同じような意味で使われます。
スクレイピングを行う方法は出来合いの有料サービスを利用する方法やプログラムを自作する方法があります。前者の例にはOctoparse等があります。後者には今回私が行ったPythonを使ったものやRubyを使ったものがあります。
BeautifulSoup4
BeautifulSoup4はHTMLからデータを収集するPythonのライブラリです。
Beautiful soupって美味しそうだよね
これを使うと簡単な構文でウェブページのデータを収集できます。
インストールは以下の通りです。
|
1 2 |
#コマンドプロンプト >pip install beautifulsoup4 |
今回はBeautifulSoup4以外に同様にウェブの情報や画像のデータを収集できるライブラリであるRequestsも使うのでこちらもインストールします。
|
1 2 |
#コマンドプロンプト >pip install requests |
実際にスクレイピングしてみよう!
それでは実際にやってみます。今回参考にしたサイトはこちらです。
ブログのタイトルを取得する
こちらのコードを参考に自分のブログのTOP ページから関連ベージのタイトルを取得することをしてみます。以下がコードです。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
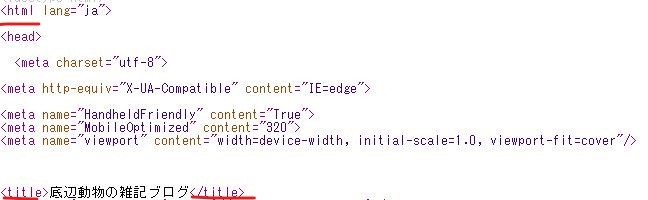
#python 3.5.1 # coding: UTF-8 import urllib.request, urllib.error#Python2 では urllib2 from bs4 import BeautifulSoup # アクセスするURL url = "https://ashikapengin.com/" # URLにアクセスする htmlが帰ってくる → <html><head><title>底辺動物の雑記ブログ</title></head><body.... html = urllib.request.urlopen(url)#python2.Xはhtml = urllib2.urlopen(url) # htmlをBeautifulSoupで扱う soup = BeautifulSoup(html, "html.parser") # タイトルを文字列を出力 print(soup.title.string) |
注意するところはPythonのバージョンによって書き方が違うということです。

正しいコードを実行した場合以下のようにタイトルが出力されます。

おおおおお!
htmlタグの中のtitleタグの1番最初の文字列を出力しているものと思います。詳しくはブログのソースを見ることで内容がわかります。ソースの表示はページで右クリックから見られます。
↓
関連ページのタイトルとURLを取得する
ウェブページ内のデータを取得するのに、関連するページ(ブログ内のURLページ)も合わせて実行したいと思うことがあると思います。
そこで、先程のコードをブログTOPの中から関連ページのタイトルとURLを取得するように修正してみます。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
#python 3.5.1 # coding: UTF-8 import urllib.request, urllib.error#Python2 では urllib2 from bs4 import BeautifulSoup # アクセスするURL url = "https://ashikapengin.com/" # URLにアクセスする htmlが帰ってくる → <html><head><title>底辺動物の雑記ブログ</title></head><body.... html = urllib.request.urlopen(url)#python2.Xはhtml = urllib2.urlopen(url) # htmlをBeautifulSoupで扱う soup = BeautifulSoup(html, "html.parser") elems = soup.select('#list a')#aタグを検索 for elem in elems:#上記で検索されたものをさらに検索 print('{} ({})'.format(elem.get("title"), elem.get('href')))#titleタグとhrefを検索 |
変わったところは下数行ですね。まずaタグの箇所を抽出してその中からタイトルとhrefを抽出します。実行した結果が以下です。

おおおおおおおおお!関連ページのタイトルとURLが出てきました。
hrefはaタグとセットで用いられる属性で、リンク先の場所を指定することができます。英語でHypertext Referenceと表されます。例えば以下のような形で書かれています。
<a href=”https://ashikapengin.com/2019/08/28/recommend-sep/” class=”○○○○○○○○” title=”【9月発売のおすすめゲーム】モンハン・二ノ国・ドラクエ・マリカー”>
| タグの取得方法 | 構文 | 使い方の例 |
| よくある方法 | soup.find_all(), soup.find() | soup.find_all(“a”, href=”/link”) |
| cssセレクタを使った方法 | soup.select() | soup.select(‘a[href^=”http://”]’) |
関連ページの中をさらに検索する
ここまできてせっかく関連ページのURLも取得できればその中も検索したいですよね。そこで、TOP画面で取得したURLを使ってさらにそのURLのページの中のURLを検索するコードに修正しました。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 |
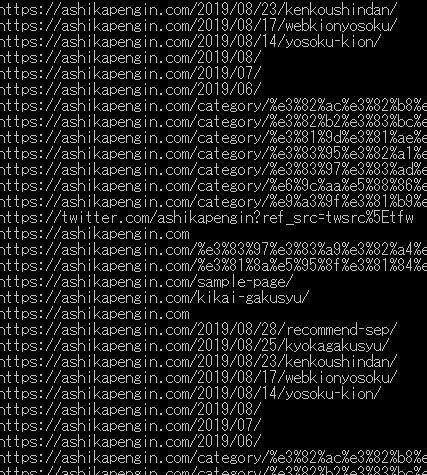
#python 3.5.1 # coding: UTF-8 import urllib.request, urllib.error#Python2 では urllib2 from bs4 import BeautifulSoup eleurl = []#URLを格納するリスト # アクセスするURL url = "https://ashikapengin.com/" # URLにアクセスする htmlが帰ってくる → <html><head><title>底辺動物の雑記ブログ</title></head><body.... html = urllib.request.urlopen(url)#python2.Xはhtml = urllib2.urlopen(url) # htmlをBeautifulSoupで扱う soup = BeautifulSoup(html, "html.parser") elems = soup.select('#list a')#aタグを検索 for elem in elems:#上記で検索されたものをさらに検索 eleurl.append(elem.get('href'))#URLを順次格納する print('{} ({})'.format(elem.get("title"), elem.get('href')))#titleタグとhrefを検索 html2 = urllib.request.urlopen(eleurl[0])# URLにアクセスする soup2 = BeautifulSoup(html2, "html.parser")# html2をBeautifulSoupで扱う elems2 = soup2.select('a[href^="https://"]')#aタグを検索 for elem in elems2:#上記で検索されたものをさらに検索 print('{}'.format(elem.get('href')))#hrefを検索 |
TOPで抽出したURLにアクセスし同様にURLを検索する。今回はとりあえずはじめに抽出したURLの中のはじめのURLに限定して検索するようにした。実行した結果が以下です。
この操作を繰り返すことでウェブページの中を網羅的に検索し必要な情報を抽出できると思います。
画像も抽出してみよう
機械学習なんかでの流行りは画像認識ですね。すると必要になるのは画像データです。そこで、画像を抽出する方法について検討してみました。参考にしたサイトはこちらです。以下が作成したコードです。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 |
#python 3.5.1 # coding: UTF-8 import urllib.request, urllib.error#Python2 では urllib2 import requests eleurl = [] # URLを格納するリスト images = [] # 画像リストの空配列 # アクセスするURL url = "https://ashikapengin.com/" # URLにアクセスする htmlが帰ってくる → <html><head><title>底辺動物の雑記ブログ</title></head><body.... html = urllib.request.urlopen(url)#python2.Xはhtml = urllib2.urlopen(url) # htmlをBeautifulSoupで扱う soup = BeautifulSoup(html, "html.parser") elems = soup.select('#list a')#aタグを検索 for elem in elems:#上記で検索されたものをさらに検索 eleurl.append(elem.get('href'))#URLを順次格納する print('{} ({})'.format(elem.get("title"), elem.get('href')))#titleタグとhrefを検索 html2 = urllib.request.urlopen(eleurl[0])# URLにアクセスする soup2 = BeautifulSoup(html2, "html.parser")# html2をBeautifulSoupで扱う for img in soup2.find_all('img'):# imgタグを検索 # コンソールへスクレイピング対象の画像URLを表示。特段必須ではない print(img.get("src")) # imagesの空配列へsrcを登録 images.append(img.get("src")) for target in images: # imagesからtargetに入れる re = requests.get(target) with open('img/' + target.split('/')[-1], 'wb') as f: # imgフォルダに格納(wbはファイルへの書き込み) f.write(re.content) # .contentにて画像データとして書き込む |
さきほどの続きでTOPページから抽出したURLのはじめのURLにアクセスし、そのページ内のイメージタグを検索して画像をダウンロードするプログラムです。
予め実行したディレクトリに「img」というフォルダを作成しておいてから実行します。実行した結果「img」内が以下のようです。

キタ━━━(゚∀゚)━━━!! 。画像がしっかりダウンロードされていますね!
これであんな画像やこんな画像も・・・
まとめ
今回はPythonのBeautifulSoup4を使ってウェブページをスクレイピングする方法について勉強してみました。
必要な情報があれば、自動で抽出できるのでかなり便利ですよね。今後これを使ってなにかできれば良いなと思っています。
ただし、スクレイピングを行う際はWebサイトの利用規約を守ることやサイトに過度な負荷をかけないことや著作権に注意すること等注意することもあることを忘れないようにしないと行けないですね。


コメント