
以降の方法ではうまく情報を取得できないことがわかりました。変更後の記事を以下に記載しましたので、ご参考にしていただければ幸いです。(2021/6/26追記)

最近色々データを見ていてもっと見やすくできないかなーと思っていました。
GIS (Geographic Information System) ソフトは地図上でデータを可視化できたり、加工できたりするものです。
このGIS上に色々情報を付与できれば面白いことができるのではないかと思いました。
ともあれ、 GISは地図が元になっています。地図上にマッピングするためには緯度経度の情報が必要となります。そこで今回はGoogleMapの検索結果すべての緯度経度情報の自動取得方法を紹介したいと思います。
GoogleChrome上での検索結果の自動抽出方法は以前のブログで紹介しているので今回はそれを改良した方法を取りたいと思います。なので以前の記事と合わせて見ていただければよりわかりやすいと思います。

私の自己流なので間違いがあったらごめんなさい。もっと良い方法があれば教えて下さい。
GoogleMap APIってなに?

緯度経度データを見つける

今回は例として検索ワード「大阪府 映画館」で調べた結果をみてみましょう。
GoogleMapを開いて検索するとこのような結果となります。
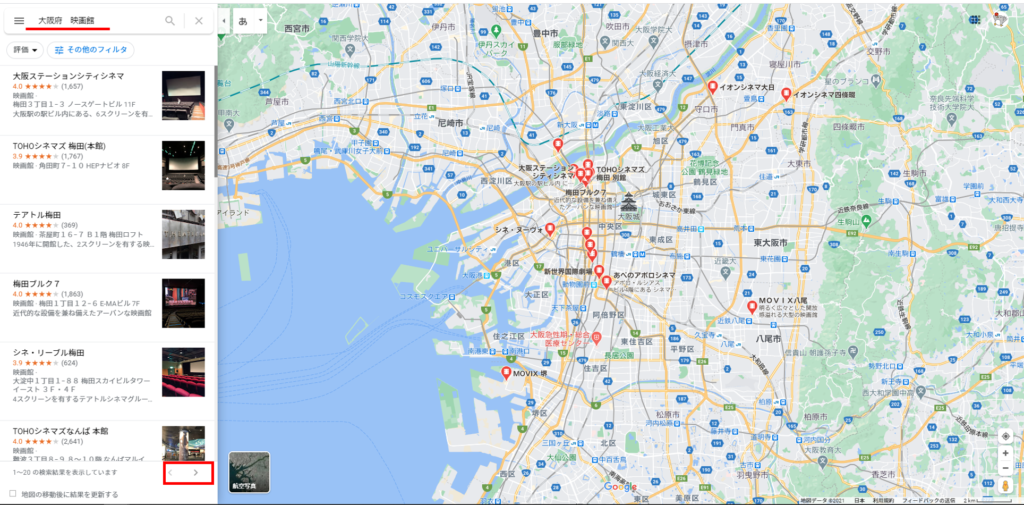
左側に詳細な情報、右側にマップです。左側の下には”次へ”のボタンがあります。
この状態で”F12“ボタンから検証を開いても緯度経度の情報は見当たりませんでした。
そこで、右側のマップの適当な位置で右クリックします。
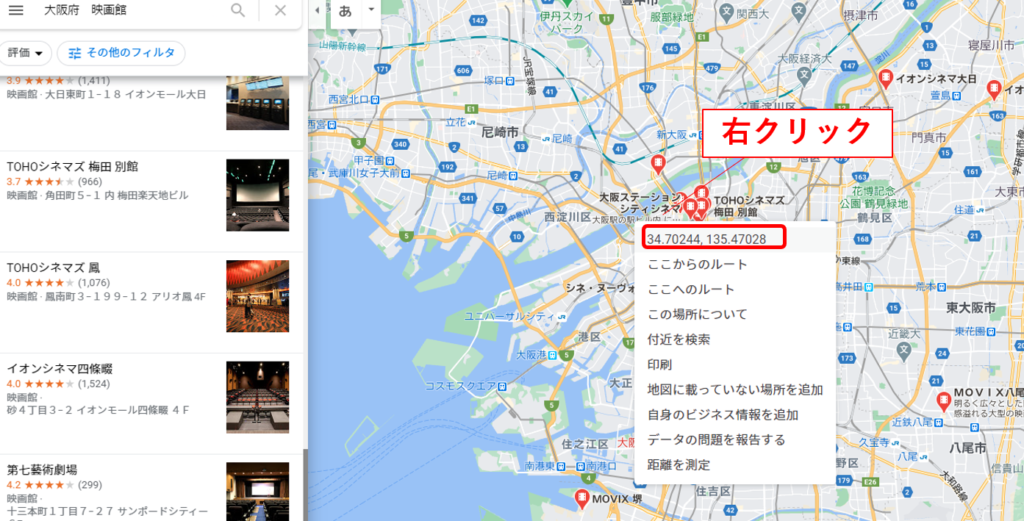
すると一番上に緯度経度の情報がでてきます。ここでこの緯度経度をクリックするとこの情報をコピーできます。ただし、この情報はマップ上で右クリックした位置になると思いますので、検索結果のピンの位置を正確に右クリックしないとその位置の情報は得られません。
しかも結局手作業になってしまうので、作業が煩雑になってしまいます。
そこで、左側の検索結果の一つをクリックしてみます。
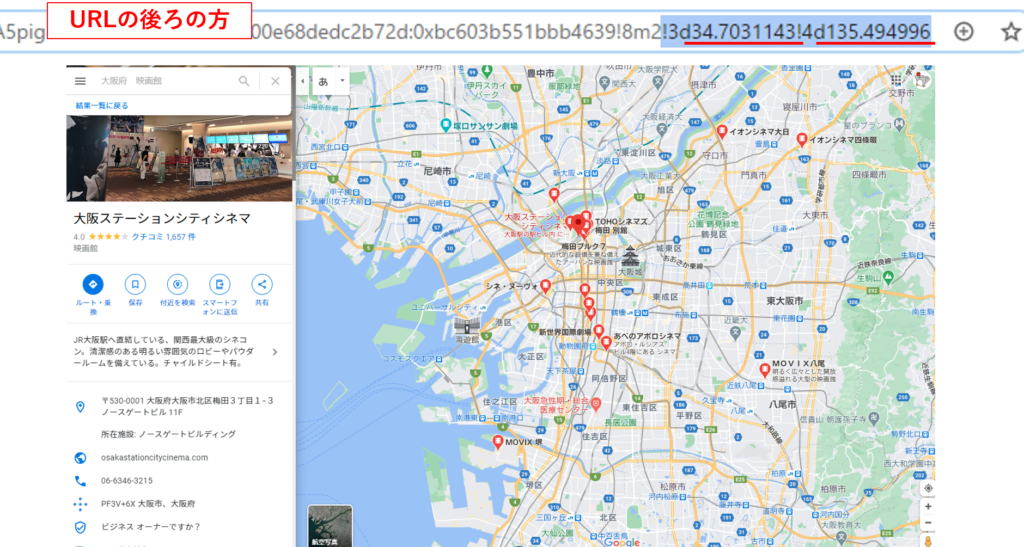
するとクリックした項目の詳細情報が表示されます。そしてこのときのURLを見てみると、その後ろの方に緯度経度らしきものがあります。たぶんこれがその地点の緯度経度だと思います。
つまりこのURLを取得できれば検索結果の緯度経度情報が取得できることになります。
流れは以下のとおりです。
① GoogleMapを開いて検索
↓
② 検索結果の一つをクリック
↓
③ URLを取得
↓
④ 結果一覧に戻る
↓
⑤ 検索結果すべてが終わるまで②~④を繰り返す
↓
⑥ 取得結果をテキストファイルに出力
プログラムのすべてを以下に示します。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 |
#Python import time from selenium import webdriver options = webdriver.ChromeOptions() # デバッグログを表示させないoption #options.add_experimental_option('excludeSwitches', ['enable-logging']) # ヘッドレスモードを有効にする(次の行をコメントアウトすると画面が表示される)。 # options.add_argument('--headless') # ChromeのWebDriverオブジェクトを作成する。 driver = webdriver.Chrome(executable_path=r"C:\chromedriver_win32\chromedriver.exe", options=options) # Googlemapのトップ画面を開く。 driver.get('https://www.google.co.jp/maps/') # HTML内で検索ボックス(name='q')を指定する search = driver.find_element_by_name('q') # 検索ワードを送信する search.send_keys('大阪府 映画館') # 検索を実行 driver.find_element_by_id("searchbox-searchbutton").click() # 5秒間待機 time.sleep(5) def ranking(driver): # ループ番号、ページ番号を定義 i = 1 # 最大何ページまで分析するかを定義 i_max = 200 # タイトルを格納する空リストを用意 title_list = [] # 緯度を格納する空リストを用意 ido_list = [] # タイトルを格納する空リストを用意 # 経度を格納する空リストを用意 keido_list = [] # URLを格納する空リストを用意 # 現在のページが指定した最大分析ページを超えるまでループする while i <= i_max: # タイトルをclass="section-result"に入っている class_group = driver.find_elements_by_css_selector('.section-result') # タイトルを抽出しリストに追加するforループ for elemnum in range(len(class_group)): # URLの遷移によるエラー対策のため再度タイトルを抽出する class_group = driver.find_elements_by_css_selector('.section-result') # class_groupのelemnum番目の要素を取得 elem = class_group[elemnum] # タイトル(class="section-result-title") title_list.append(elem.find_element_by_css_selector('.section-result-title').text) # 次へのボタンをクリック(class="section-result-content") elem.find_element_by_class_name('section-result-content').click() # 3秒間待機 time.sleep(3) # クリック先のURLの取得 txt = driver.current_url # 取得したURLの文字列の中から"!3d"の位置を見つける pos = txt.find('!3d') # "!3d"の位置から!3dを除いた後ろの文字列を取得する txt2 = driver.current_url[pos+3:] # さらに"!4d"で文字列を分割 txt3 = txt2.split('!4d') # 分割した文字列の前側が緯度 ido_list.append(txt3[0]) # 分割した文字列の後側が緯度 keido_list.append(txt3[1]) # "結果一覧に戻る"ボタンをクリック(class="section-back-to-list-button.blue-link.noprint") driver.find_element_by_css_selector('.section-back-to-list-button.blue-link.noprint').click() # 3秒間待機 time.sleep(3) # 次ページボタンがあると試す try: # 次ページをクリック driver.find_element_by_id('n7lv7yjyC35__section-pagination-button-next').click() # iを更新 i = i + 1 # 5秒間待機 time.sleep(5) # 次ページボタンがない場合は終了する except: i = i_max + 1 # タイトルとリンクのリストを戻り値に指定 return title_list, ido_list, keido_list # ranking関数を実行してタイトルとURLリストを取得する title, ido, keido= ranking(driver) # タイトルリストをテキストに保存 with open('title.txt', mode='w', encoding='utf-8') as f: f.write("\n".join(title)) # 緯度リストをテキストに保存 with open('ido.txt', mode='w', encoding='utf-8') as f: f.write("\n".join(ido)) # 経度リストをテキストに保存 with open('keido.txt', mode='w', encoding='utf-8') as f: f.write("\n".join(keido)) # ブラウザを閉じる driver.quit() |
出力された”title.txt“、”ido.txt“、”keido.txt“の中身は以下のようになります。
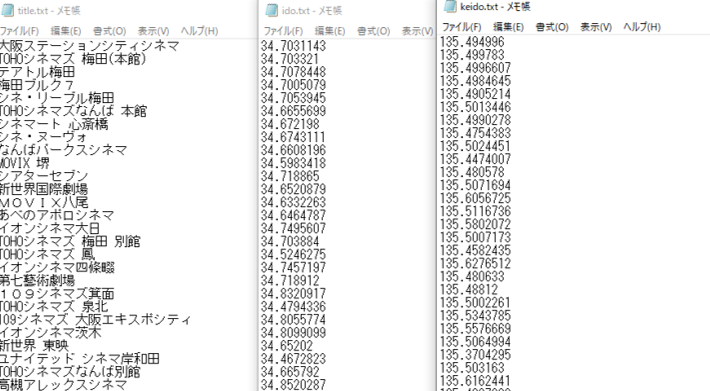
無事に取得できてますね!
コードの注意点

コメントに処理内容を示していますが、上記のコードの中で私が引っかかった注意点等を示します。
forループ中の画面遷移時のclass属性の取得
41行目でなぜもう一度”class_group“を取得しているかというと、一度検索結果の一つをクリックして画面遷移が発生すると結果一覧に戻ったときに前に取得した“class_group”が使用できなかったためです。そこで、一覧に戻るたびに”class_group”を取得してループの回数で検索結果の何番目かということを把握しています。
URL文字列の取得
47行目以降のURLの取得についてですが、現在のURLの取得は”selenium”では、以下で取得できます。
|
1 2 3 |
#Python # クリック先のURLの取得 txt = driver.current_url |
URLから緯度経度の情報だけを取得するには、前方のいらない部分を削除する必要があります。それが以下の部分です。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
#Python # クリック先のURLの取得 txt = driver.current_url # 取得したURLの文字列の中から"!3d"の位置を見つける pos = txt.find('!3d') # "!3d"の位置から!3dを除いた後ろの文字列を取得する txt2 = driver.current_url[pos+3:] # さらに"!4d"で文字列を分割 txt3 = txt2.split('!4d') # 分割した文字列の前側が緯度 ido_list.append(txt3[0]) # 分割した文字列の後側が緯度 keido_list.append(txt3[1]) |
文字列の扱いについてはこちらのサイトを参考にしました。注意点としては、今回のケースは緯度経度の後ろになにもないURLでしたが、検索の仕方によっては経度の後ろにも文字列が続くケースがあります。
この場合はその後ろの部分を除く必要があります。いらない部分が17文字であれば先の7行目を以下のように変更すれば良いと思います。
|
1 2 3 |
#Python # "!3d"の位置から!3dを除いた後ろの文字列を取得する.さらに最終文字から17文字を削除 txt2 = driver.current_url[pos+3:-17] |
時間がかかる
これはしょうがないかもしれませんが、今回の方法では、画面遷移が頻発します。そのため”time.sleep()”は発生してしまい。検索結果が多いとまあまあ時間がかかります。今回の”大阪府 映画館”の場合は54件と比較的少なかったものの5分ほどかかりました。
これはパソコンの性能であまりどうこうできる話ではないと思うので、画面遷移が発生しない別の方法を模索する必要があるかもしれません。
まとめ
以上GoogleMapの検索結果の緯度経度情報の取得方法の紹介でした。
まだまだ勉強不足で遠回りしている部分があるかもしれませんが、一応目的のものが取得できました。
今後はこの結果を応用してみたいと思っています。


コメント
初めまして。
ど初心者です。偶然見つけて面白そうなので、学習教材として勉強させていただいております。
実行したところ、”title.txt“、”ido.txt“、”keido.txt“が0㎅で何も出力されませんでした。
いろいろ試したところ、自分なりに以下で何か調整が必要なのかなと考えました。
※うまく読み込めないとか・・・
# タイトルをclass=”section-result”に入っている
class_group = driver.find_elements_by_css_selector(‘.section-result’)
いったんうまく動いてくれると嬉しいです。
→回避策とか教えていただけたら大変助かります。
それでもスクレイピングの習い初めにいいアイディアの記事だと思いますので感謝です。
面白い記事楽しみにしております。
いがっぺおじさん様
コメント誠にありがとうございます。
あしかぺんぎんです。
いがっぺさんのおっしゃる通りclass=”section-result”以降が機能していません。
おそらく最近Googlemapの仕様が変わってしまったからだと思います。
変更後に対応した記事を作成したいと思いますので、もうしばらくお待ちいただけますでしょうか。
お待たせしてしまって申し訳ございません。
何卒よろしくお願いいたします。
あしかぺんぎん様
ご丁寧な返信ありがとうございます。
やはりそうでしたかぁ・・・といっても手が出せず記事楽しみにしています。
自分でも調べてはみますが、何しろにわか学習なもので分からず。
コマンド本も買いましたよ。
でも、うまくいけばうれしい機能だと思いますよ。
何卒よろしくお願いいたします。
※バイクツーリングが好きなので気になる地名とか調べてみたいです(峠とか岬とかいろいろ)。
いがっぺおじさん様
ご返信ありがとうございます。
新しい記事を作成しました。
https://ashikapengin.com/2021/06/26/scraping4/
おそらく今後もGoogleMapの仕様が変わることが予想されます。
コマンド本の知識があれば、簡単に修正できるものだと思いますので、
都度参考にしていただければと思います。
素敵な趣味のお役に立てればと思います。
また何かございましたら気軽にコメントください。
よろしくお願いします。