
Pythonを使ってGoogleから特定キーワードで検索した結果のタイトルとURLを自動抽出するプログラムを勉強したので、備忘録がてら記事にしたいと思います。
今回実施した環境は Anacondaで pythonのバージョンは3.6.10です。
スクレイピングの記事は以前にも書いてたので参考までに掲載しておきます。


プログラム全体
前回はPythonのモジュールである”BeautifulSoup“を使用しておりましたが、今回は別のモジュールである”selenium“というものを使用しました。seleniumのモジュールをインストールしていない場合は以下のコマンドをAnaconda promptで入力すればインストールできます。
|
1 2 |
#Anaconda Prompt >conda install selenium |
今回作成したプログラムの内容は主にこちらのサイトとこちらのサイトを参考にしております。そして最近のアップデートのせいかわかりませんが、そのとおりにコピーしてもうまく作動しなかったのですこし改良して動くようにしました。
まずすべてのソースを以下に記載します。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 |
#python import time from selenium import webdriver options = webdriver.ChromeOptions() # デバッグログを表示させないoption #options.add_experimental_option('excludeSwitches', ['enable-logging']) # ヘッドレスモードを有効にする。 # options.add_argument('--headless') # ChromeのWebDriverオブジェクトを作成する。 driver = webdriver.Chrome(executable_path=r"C:\chromedriver_win32\chromedriver.exe", options=options) # Googleのトップ画面を開く。 driver.get('https://www.google.com/') # HTML内で検索ボックス(name='q')を指定する search = driver.find_element_by_name('q') # 検索ワードを送信する search.send_keys('底辺動物') # 検索を実行 search.submit() # 5秒間待機 time.sleep(5) def ranking(driver): # ループ番号、ページ番号を定義 i = 1 # 最大何ページまで分析するかを定義 i_max = 2 # タイトルを格納する空リストを用意 title_list = [] # URLを格納する空リストを用意 link_list = [] # 現在のページが指定した最大分析ページを超えるまでループする while i <= i_max: # タイトルとリンクはclass="yuRUbf"に入っている class_group = driver.find_elements_by_css_selector('.yuRUbf') # タイトルとリンクを抽出しリストに追加するforループ for elem in class_group: #タイトル(class="LC20lb DKV0Md") title_list.append(elem.find_element_by_css_selector('.LC20lb.DKV0Md').text) #リンク(aタグのhref属性) link_list.append(elem.find_element_by_tag_name('a').get_attribute('href')) # 「次へ」は1つしかないが、あえてelementsで複数検索。空のリストであれば最終ページの意味になる。 if driver.find_elements_by_id('pnnext') == []: i = i_max + 1 else: # 次ページのURLはid="pnnext"のhref属性 next_page = driver.find_element_by_id('pnnext').get_attribute('href') # 次ページへ遷移する driver.get(next_page) # iを更新 i = i + 1 # 5秒間待機 time.sleep(5) # タイトルとリンクのリストを戻り値に指定 return title_list, link_list # ranking関数を実行してタイトルとURLリストを取得する title, link = ranking(driver) # タイトルリストをテキストに保存 with open('title.txt', mode='w', encoding='utf-8') as f: f.write("\n".join(title)) # URLリストをテキストに保存 with open('link.txt', mode='w', encoding='utf-8') as f: f.write("\n".join(link)) # ブラウザを閉じる driver.quit() |
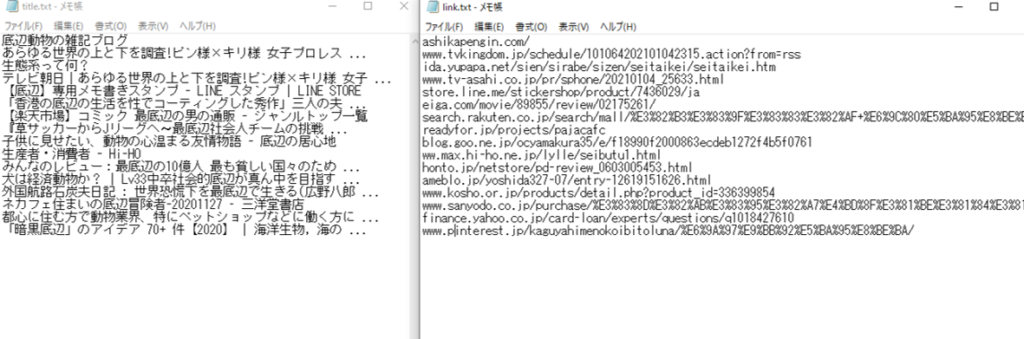
出力される”title.txt”と”link.txt”の中身はこんな感じです。うまくできました。
プログラムの流れは以下のとおりです。
Googleを起動
↓
検索ワード「底辺動物」で検索
↓
指定ページ数に到達するまでタイトルとサイトURLを取得
↓
取得したタイトルとサイトURLをテキストファイルに出力
以上です。
詳しい解説は参考サイトに記載があるため今回は細かい改良点と行き詰まった点を記載します。
chromedriverのダウンロード
今回は自動でgoogle検索するために”chromedriver“というものを使用しています。
chromedriverはこちらのサイトでダウンロードできます。
注意するのはダウンロードするバージョンです。普段使っているGoogleChromeと同じバージョンをダウンロードします。
普段使っているGoogleChromeのバージョンは以下の通り設定のChromeについてから確認できます。
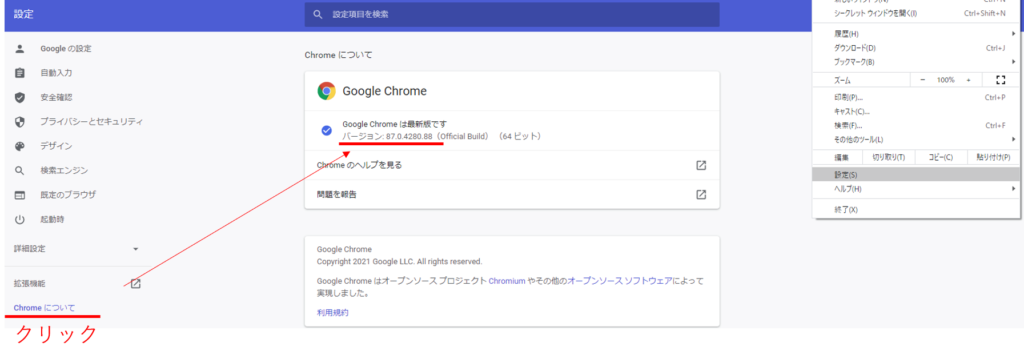
これを同じにしないとエラーが発生したので注意しないと行けないと思います。
そしてプログラム11行目の通りダウンロードしたディレクトリを参照します。
Driverのoption
ドライバーオブジェクトを作成するときにoptionをつけると色々なオプションが使用できます。上記のプログラムではコメントアウトしていますが、コンソールにデバッグログを表示させない以下のものや、
|
1 2 3 |
#python # デバッグログを表示させないoption #options.add_experimental_option('excludeSwitches', ['enable-logging']) |
Chromeがいちいち起動するのが煩わしい際に使用できる以下のヘッドレスモードもあります。
|
1 2 3 |
#python # ヘッドレスモードを有効にするoption options.add_argument('--headless') |
タイトルclassの取得
今回行き詰まったのはタイトルのclassの取得です。これは調べたとおりには行かずChromeの検証から調べました。プログラムの以下の部分です。
|
1 2 3 4 5 6 7 8 9 |
#python # タイトルとリンクはclass="yuRUbf"に入っている class_group = driver.find_elements_by_css_selector('.yuRUbf') # タイトルとリンクを抽出しリストに追加するforループ for elem in class_group: #タイトル(class="LC20lb DKV0Md") title_list.append(elem.find_element_by_css_selector('.LC20lb.DKV0Md').text) #リンク(aタグのhref属性) link_list.append(elem.find_element_by_tag_name('a').get_attribute('href')) |
調べ直した結果以下の通りタイトルが入っていたのは”LC20lb DKV0Md“というclassでした。
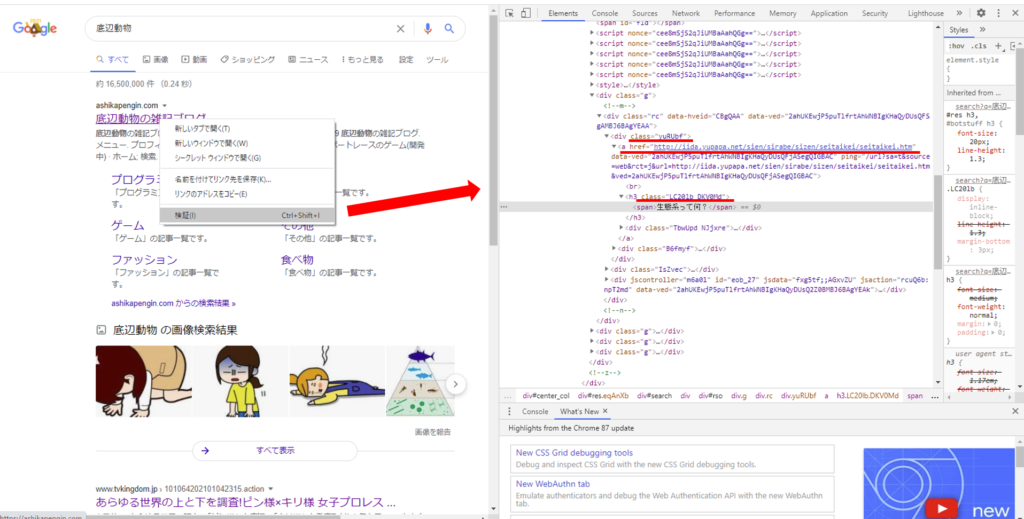
classを取得するには以下のコマンドを使います。
|
1 2 |
#python driver.find_element_by_class_name("LC20lb DKV0Md") |
ただしこれではうまくいきません。classに空白がある場合は”css_selector“というものを使うみたいです。”selenium”のアップデートで変わったとか?
修正したものが今回のプログラムで使っているものです。class名の前に”.”をつけ空白は”.”で置き換えます。
これでうまくいきました!やれやれ😢
まとめ
ひさびさにPythonでスクレイピングやってみました。初心者ですが、やっぱり楽しいですね(*^^*)
スクレイピングできれば、色々作業も捗りそうですね!
またちょこちょこやっていきたいです。
- chromedriverのバージョンに注意
- driverのオプション機能は割と使える
- classの取得方法に注意


コメント