
本当はもう少し前に投稿すべき内容ですが、時間がかかってしまいました。
2022年の今年の漢字は「戦」でしたね。これは全国からの募集により日本漢字能力検定協会が発表しているみたいです。確かに戦争やスポーツなどで戦いが多い年だったかもしれません。
でもまあせっかくpythonを勉強しているので、2022年の漢字をネットの情報から分析できないかを考えました。
はじめはネットニュースの記事の内容やタイトルからデータをスクレイピングして、分析しようと思ったのですが、ネット記事の多くは公開期限が決まっているみたいで、2022年1月からのデータを分析するには有料会員になるなどお金がかかることがわかったので、その方法は辞めました
別の方法で、ネットの情報ということでTwitterのトレンドだったら「2022年の流行り=2022年の漢字」がわかると考え、そちらの方法で漢字を抽出することにしました。
漢字分析の流れ
Twitterのトレンドの抽出ですがどうしようか考えていたのですが、「Trend Calendar」というすばらしいサイトがありましたので、こちらのサイトからトレンドをスクレイピングすることにしました。
こちらのサイトにはTwitter以外にもGoogleのトレンドワードも記載されていましたので同時に分析することにしました。
トレンドの抽出と漢字分析の流れは以下のとおりとしました。
- Trend Calendarからトレンドワードを抽出する(Selenium4)。
- 抽出したトレンドワードから漢字を抽出(単語を抽出する場合はMecab)して、漢字の出現回数を計算して多いものを抽出する(Gensim)。
1. TwitterのトレンドとGoogleの検索ワードのスクレイピング
「Trend Calendar」のURLは「”https://jp.trend-calendar.com/trend/”+日付+”.html”」となっているため日付を増やしながらURLにアクセスして各日付のトレンドワードを抽出します。
スクレイピングにはSelenium4を使用しました。Selenium3と4で色々仕様が変わっている見たでしたので注意してください(例えば要素の取得方法など)。
なお、トレンドランキングの15位以降については「もっと見る」ボタンをクリックする必要があり煩わしかったので、もともと表示されている15位までを取得することにしました。
プログラムを以下に記載します。解説はコメントで書きました。関数内の要素ループはTwitterとGoogleで同じなのでまとめても良かったですね。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 |
# python from selenium import webdriver from selenium.webdriver.common.by import By from selenium.webdriver.support.ui import WebDriverWait from selenium.webdriver.support import expected_conditions as EC from selenium.webdriver.chrome import service as fs from selenium.webdriver.chrome.options import Options import pandas as pd import numpy as np import datetime # Seleniumの起動オプション chrome_options = Options() # chromeとchromedriverを開いたままにしておきたい場合のオプション chrome_options.add_experimental_option("detach", True) # SSL認証を無効 chrome_options.add_argument('--ignore-certificate-errors') chrome_options.add_argument('--ignore-ssl-errors') # Chromeのドライバーを使用(chromedriver.exeは別途ダウンロード) CHROMEDRIVER = "chromedriver.exe" # ドライバー指定でChromeブラウザを開く chrome_service = fs.Service(executable_path=CHROMEDRIVER) driver = webdriver.Chrome(service=chrome_service) url = "https://jp.trend-calendar.com/" # urlに移動 driver.get(url) # 最大の待機時間を指定(100秒) wait = WebDriverWait(driver, 100) # 空のデータフレームを作成するための元になるDataFrame(15位までなので15行確保) df = pd.DataFrame(np.random.random([15, 3]), columns=['foo', 'bar', 'baz']) # Twitter用の空データフレーム df_t = pd.DataFrame(index=df.index, columns=[]) # Google用の空データフレーム df_g = pd.DataFrame(index=df.index, columns=[]) # スクレイピングする関数(日付,Twitterのデータフレーム, Googleのデータフレーム) def getContent(date,df_t,df_g): # urlを作成 url = "https://jp.trend-calendar.com/trend/"+date # urlに移動 driver.get(url) # 適当な要素を指定 selector = '#google > div > div:nth-child(1)' # 指定された要素が表示状態になるまで待機する element = wait. until(EC.visibility_of_element_located((By.CSS_SELECTOR, selector))) # スクレイピング結果を格納するリスト tlist = [] glist = [] # 日付の要素 pagedate =driver.find_element(By.CLASS_NAME, "entry-title") # classでの指定 # Twitterの要素 element = driver.find_element(By.ID, "twitter") # idでの指定 # Twitterの要素の各順位の要素 element = element.find_elements(By.CLASS_NAME, "readmoretable_line") # classでの指定 # 取得した要素でループ for ele in element: # 取得した要素を"."で分割 textlist = ele.text.split(".") # 順位が空の場合は次のループへ if textlist[0] == "": continue # 抽出したワードをリストに格納する(lstripは不要文字の削除のため) tlist.append(textlist[1].lstrip()) # 作成したリストをデータフレームに結合する df_tp=pd.concat([df_t,pd.Series(tlist)], axis=1) # データフレームの列名を日付要素の日付部分に変更 df_tnew = df_tp.rename(columns={0: pagedate.text.rstrip("のトレンドワード")}) # Googleの要素 element = driver.find_element(By.ID, "google") # idでの指定 # Googleの要素の各順位の要素 element = element.find_elements(By.CLASS_NAME, "readmoretable_line") # classでの指定 # 取得した要素でループ for ele in element: # 取得した要素を"."で分割 textlist = ele.text.split(".") # 順位が空の場合は次のループへ if textlist[0] == "": continue # 抽出したワードをリストに格納する(lstripは不要文字の削除のため) glist.append(textlist[1].lstrip()) # 作成したリストをデータフレームに結合する df_gp=pd.concat([df_g,pd.Series(glist)], axis=1) # データフレームの列名を日付要素の日付部分に変更 df_gnew = df_gp.rename(columns={0: pagedate.text.rstrip("のトレンドワード")}) # 作成したデータフレームを返す return df_tnew,df_gnew # 最初の日付 d1 = datetime.date(2022, 1, 1) # 日付でループする(340は取得する日数) for i in range(340): # 日付を文字列にする d1str =d1.strftime('%Y-%m-%d') # urlを作成 date = d1str+".html" print(date) # 一日増やす d1 += datetime.timedelta(days=1) # エラーの場合はスルーする try: df_t,df_g = getContent(date,df_t,df_g) except: print("error") pass # ブラウザを閉じる driver.close() # 作成したデータフレームをCSVに出力 df_t.to_csv("df_t.csv", encoding = "UTF-8") df_g.to_csv("df_g.csv", encoding = "UTF-8") |
抽出したCSV(df_t.csv)は以下のような感じになります。エンコードがUFT-8であることに注意してください。
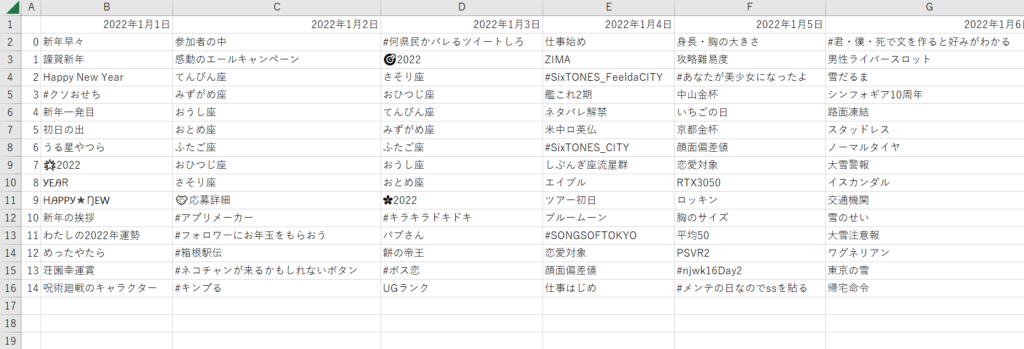
2. 漢字の抽出と出現回数の計算
トレンドワードを抽出したので、ここから漢字を抽出します。
他の方法はあるかもしれませんが、今回はGensimを使って辞書を作成して、漢字の出現回数を算出します。Gensimの辞書はテキストファイルに出力すると「id, 単語, 出現文書数」の形式で出力されるので、これを使ってエクセルで出現回数順で並べ替えて集計しました。
Gensimを使えば自然言語処理としてもっといろんなことができるため、今後の分析に色々活用していきたいと思っています。
また、Mecabは日本語の形態素解析によく用いられるシステムで、文章を名詞、動詞、形容詞、など細かい単語に分解してくれます。今回は漢字以外にこれを使って単語の出現回数も集計しました。
あと、WordCloudですが、これは単語を頻度に比例する大きさで雲のように並べたもので、出現回数を可視化したものです。ぱっと見でわかりやすいので、単語の分析の際につかってみました。
作成したプログラムを以下に記載します。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 |
#python import pandas as pd import MeCab import unidic import regex from gensim.corpora import Dictionary from wordcloud import WordCloud # csvからワードを抽出する関数 def makeList(file_name): # csvの中身をデータフレームとして抽出 input = pd.read_csv(file_name, index_col=0) # 漢字の正規表現 p = regex.compile(r'\p{Script=Han}+') # MecabのTaggerクラス(単語を抽出するときに使う) tagger = MeCab.Tagger("-Owakati") # 漢字,単語,クラウドワード用のリスト textlist = [] wordlist = [] cloudlist = [] # 列のループ for j in range(len(input.columns)): # 行のループ for i in range(len(input)): # 文字以外はスルー if type(input.iloc[i, j]) is str: # 漢字を一文字ずつに分割 retextlist = [[l] for l in list(input.iloc[i, j]) if p.fullmatch(l)] # リストに格納 textlist.extend(retextlist) # 単語に分割 result = tagger.parse(input.iloc[i, j]).split() # 1文字の単語は無視する rewordlist = [l for l in result if p.fullmatch(l) and len(l) > 1] # リストに格納 wordlist.append(rewordlist) # ワードクラウド用に格納 cloudlist.extend(rewordlist) # それぞれのリストを返す return textlist, wordlist, cloudlist # 抽出すつcsvの名前 input_file_name = 'df_g.csv' # csvからリストを作成 textlist, wordlist, cloudlist = makeList(input_file_name) # 漢字についてgensimの辞書を作成 textdct = Dictionary(textlist) # 辞書をテキストファイルとして保存 textdct.save_as_text('textdct.txt') # 単語についてgensimの辞書を作成 worddct = Dictionary(wordlist) # 辞書をテキストファイルとして保存 worddct.save_as_text('worddct.txt') # ワードクラウド用にリストを加工 text = " ".join(cloudlist) # Windowsにインストールされているフォントを指定 wordcloud = WordCloud(font_path='C:/Windows/Fonts/HGRSGU.TTC',background_color='white',min_font_size=15) # ワードクラウドの作成 wordcloud.generate(text) # 画像を保存 wordcloud.to_file('wc.jpg') |
集計結果
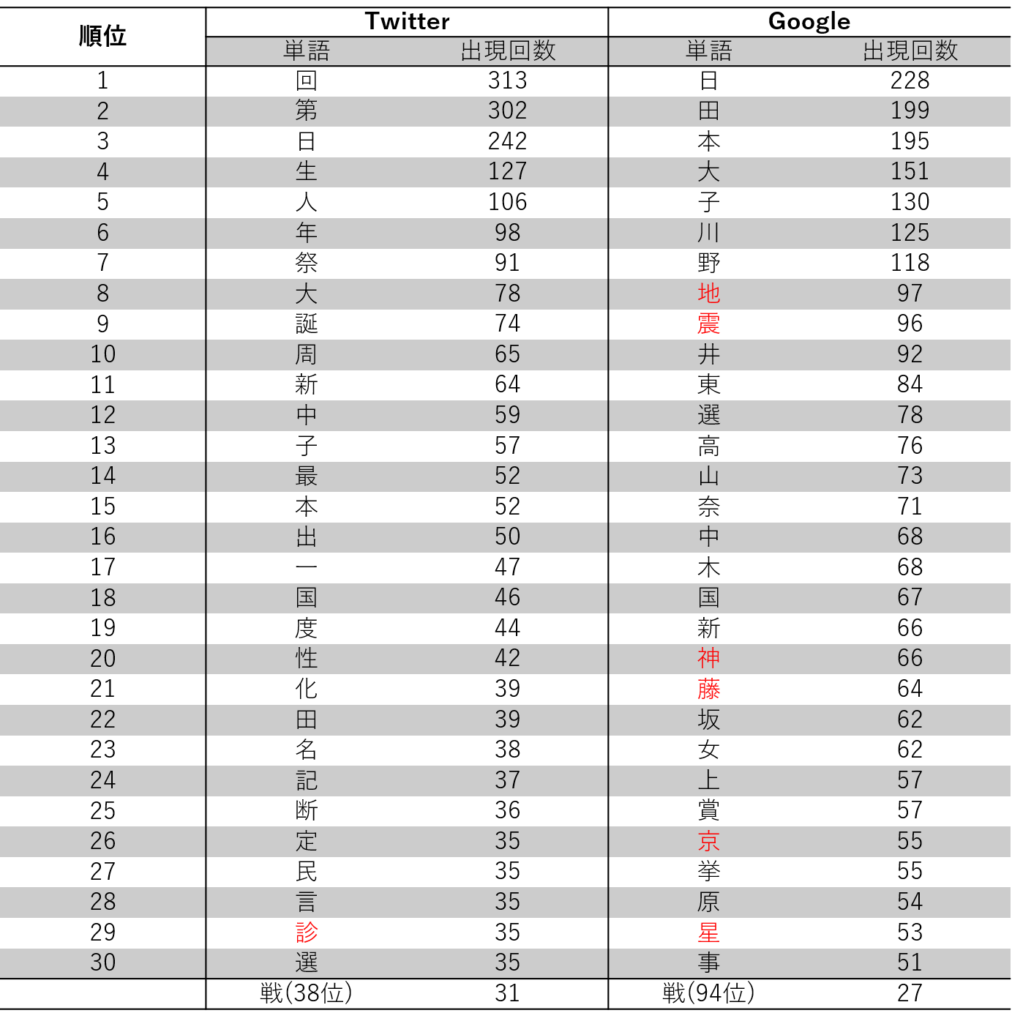
漢字の分析結果
漢字について、集計した結果を以下に示します。単に出現回数であれば、「回」「日」などが多いのですが、これらはトレンドと言うよりか普段から使う漢字なので、2022の漢字とはいえない気がします。
他にもそういった理由を考慮するとそれっぽい漢字は赤字で示したような、地震を表す「地」「震」や、医療関係を表す「診」、月食?に関係する「星」などかなという印象です。あくまで個人の印象なので、なかなか判断は難しいですね。
いずれにしても「戦」はTwitterでは38位と割りと上位に入っているため、2022年の漢字として比較的妥当な結果であるのではないでしょうか。
また、TwitterとGoogleで違いが有るのも興味深いですね。
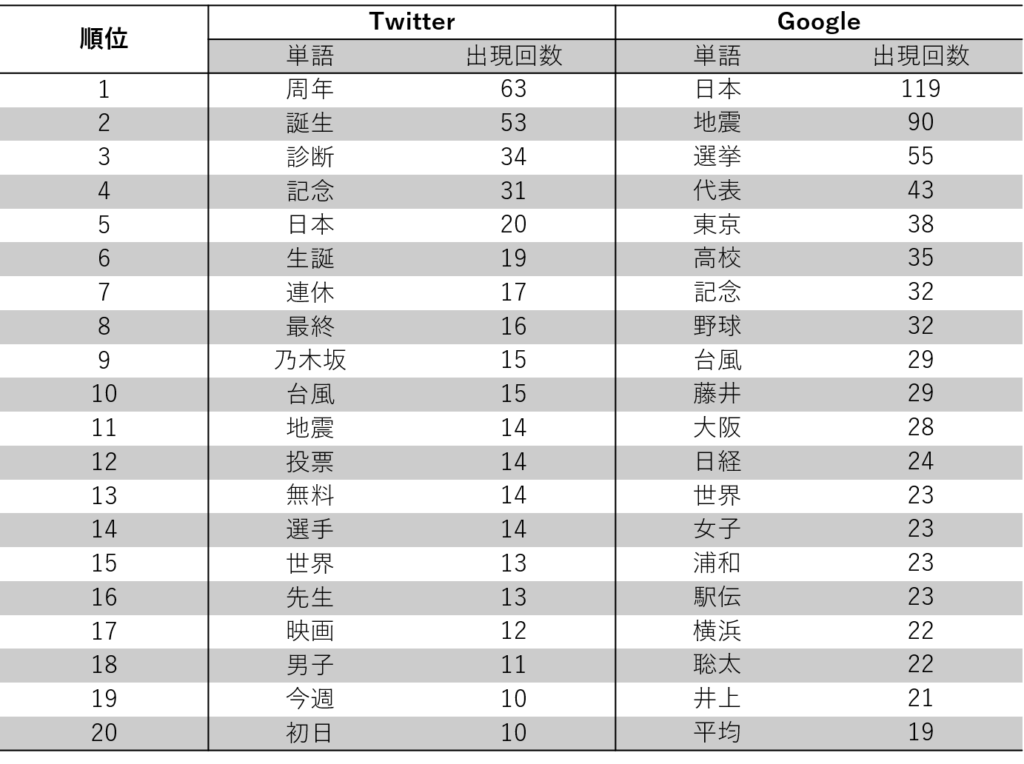
単語の分析結果
単語について、集計した結果を以下に示します。どうでしょうか、単語で診ると漢字で多かった「地震」などに加えて、政治的ワードの「選挙」や個人やチームを示す「藤井」、「乃木坂」なんかもランクインしていることがわかり面白いですね。
この結果のワードクラウドを載せておきます。よりわかりやすいと思います。


まとめ
今回はpythonを使って2022年の漢字を分析してみました。
最終的な結果には個人的な判断が入るので、難しいですが、機械的に単語の出現回数を取得できることがわかったので、今後文章のトレンド分析などに活かせるのではないかと思っています。
自然言語処理にも興味があるので、そのへんも勉強していきたいですね。
参考サイト
- 今日のトレンドワード
- Selenium4ではfind_element_by_id、nameは非推奨
- 【Python】visibility_of_element_located・・・指定した要素が表示されるまで待機する
- Selenium + Headless Chromeで証明書エラーを回避する
- 【Python3】SeleniumのChrome起動オプションについて
- 【Python】Seleniumでの待機処理(暗黙的な待機、明示的な待機)
- 【Python】Seleniumの待機処理でtime.sleepを絶対に使用してはいけないという教訓
- Python – 文字列を1文字ずつ分割してリストに入れる
- Mecabの使い方を知る【 Taggerクラス】
- gensimのDictionaryの中身を簡単にまとめてみた

コメント