
最近プログラム関係の勉強としてUnityで遊んでいた関係でPythonの勉強がなかなか疎かになっていました。
そこで今回はPythonの勉強の一環で、私が予てよりやってみたかった機械学習に挑戦してみました。
機械学習
機械学習はモデルを多くのデータから学習することを指すみたいです。いろんな情報を持つデータからその現象の特徴をとなる要因を抽出してモデルを構築するみたいなイメージでしょうか。
難しいことは調べれば色々出てくると思いますので、そちらにおまかせします。私は以下の本を少し読んで1/100くらい理解しました。

例としては最近だと文字認識や画像認識が有名だと思います。あとは「OK google」でおなじみのGoogle homeや「Hey Siri」でおなじみのiPhoneのSiriなんかも音声を認識して適切な返答をするといった機能がそれにあたる思います。
このように世間にも注目されている機械学習ですが、Pythonにはこの機械学習が簡単に行えるライブラリが色々存在します!
こちらのHPに詳細はまとめてありましたが、私が実際触ったものだとTensorFlowやscikit-learnなんかがあります。
scikit-learnはPythonの機械学習のオープンソースライブラリで、Pythonの数値計算ライブラリのNumpyやScipyとやり取りするように設計されているなどPythonでコードを書くには使いやすい仕様となっています。
ただし、今回は有名で参考書もたくさん出版されているTensorFlowを使うことにします。そう言いつつもscikit-learnには機械学習以外にも便利な関数があるので、データを加工するのに使います。
- Googleが開発した人工知能エンジンをオープンソース化したもの
- C++, Java, Pythonなどの言語に対応している
- コードの記述が簡潔である
TensorFlowの他にTensorFlow上で動くライブラリであるKerasも使います。Keras(=ケラス)を使うことでより手軽に機械学習のコードを書くことができるらしいです。私が参考にしたコードもKerasを使っていたため使いたいと思います。
データの準備とコードの作成!
ん~いざ機械学習といっても何を予測しようか迷いました。株価で一攫千金?画像認識で人物判別?
色々考えましたがはじめはオーソドックスなことで私がやりたいことに近いことで気温の予測をしてみることにします。
イメージとしては複数の気象要素から気温を予測するみたいな感じです。
データの取得と加工
とりあえずもととなるデータを取得します。気象庁のHPからアメダス観測点の各データがダウンロードできるので今回はそちらを利用しました。
とりあえず今回はアメダス観測所「東京」の2014年1月1日~2018年12月31日までの日ごとの以下のデータをダウンロードしました。
- 降水量の日合計
- 日平均現地気圧
- 日平均相対湿度
- 日平均気温←今回の予測の対象
- 日照時間
この他にもダウンロードできる気象要素はありましたが、今回は独断と偏見でこれらの要素をもとに気温を予測していきたいと思います。なので、もしかしたらもっと気温予測に適した気象要素があるかもしれませんがご了承下さい。
またデータの期間についても5年間としましたが、この数についても検討の余地はあると思います。
ダウンロードしたデータ(csvファイル)の中身は以下のような感じ
んーなんかごちゃごちゃしてますね。後にこのcsvを読み込んで学習するのですが、このままでしゃ処理が大変(私の能力が足りない)なので、ここでデータを以下のように加工します。
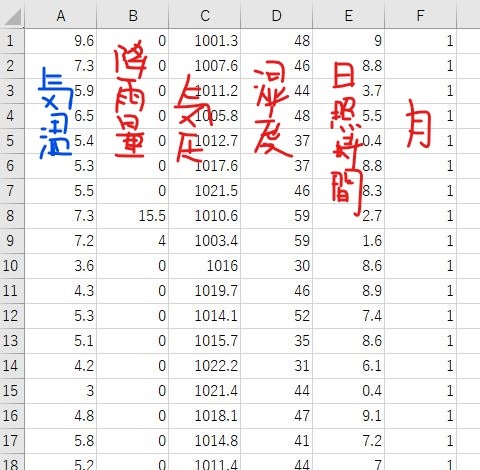
A列が今回予測の目的となる気温、他が予測のもととなる変数ですね。
これでデータの準備はできました。それでは機械学習のコードを書いていきます。
機械学習のコード
そんなに長くないので今回のコードを以下に載せます。
ざっくり説明すると、
- 先程準備したデータを学習用とテスト用に分割します(8:2)。
- 学習用を使ってモデルに学習させます。
- 学習させたモデルを使って正解の気温を比較して精度を算出します。
- 最後にモデルを使ってテスト用のデータから気温を予測します。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 |
# encoding: utf-8 import keras import numpy as np import pandas as pd from sklearn import preprocessing from sklearn.model_selection import train_test_split from keras.models import Sequential, model_from_json from keras.layers.core import Dense from keras.optimizers import RMSprop import matplotlib.pyplot as plt def plot_history(history): plt.plot(history.history['acc']) #plt.plot(history.history['val_loss']) plt.title('model accuracy : ') plt.ylabel('accuracy') plt.xlabel('epoch') plt.legend(['train', 'test'], loc='upper left') plt.savefig('accuracy.png') plt.close() # CSVファイルの読み込み df = np.loadtxt('data2.csv', delimiter=",", dtype=float,encoding="utf-8_sig") # 目的変数を取り出す(気温の列) y = df[:, 0:1] # 説明変数を取り出す(ここでは気圧と湿度と日照時間の3列)。その際に列ごとに正規化 X = preprocessing.minmax_scale(df[:, 2:5]) # 学習用、テスト用にデータを分割(1:1) X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2) ##########################################ここから学習 model = Sequential() # 入力層 model.add(Dense(10, activation='sigmoid', input_shape=(3,))) # 出力層 model.add(Dense(1, activation='linear')) # コンパイル(勾配法:RMSprop、損失関数:mean_squared_error、評価関数:accuracy) model.compile(loss='mean_squared_error', optimizer=RMSprop(), metrics=['accuracy']) # 構築したモデルで学習 history = model.fit(X_train, y_train, batch_size=20, epochs=300) # モデルの性能評価 score = model.evaluate(X_train, y_train, verbose=0) print('Score:', score[0]) # 損失値 print('Accuracy:', score[1]) # 精度 # 学習履歴をプロット plot_history(history) # モデルを使った予測 y_ = model.predict(X_test) # 予測と正解のグラフ作成 p1 = plt.plot(y_test) p2 = plt.plot(y_) plt.savefig('pre.png') plt.show() # 予測と正解の出力 data = np.c_[y_test,y_] np.savetxt('out.csv',data,delimiter=',') # 学習モデルの保存 model.save('and.h5') |
参考にさせていただいたサイトはこちらとこちらです。ほぼこちらのものを流用しました。
機械学習のパラメータについては完全に理解するにはかなり勉強する必要がありそうですが、いろんなパラメータを試した結果今回のもので行くことにしました。
予測してみる!
まずはそのまま
まずはデータにあった5要素すべてをつかったときの気温を予測結果を以下に示します。
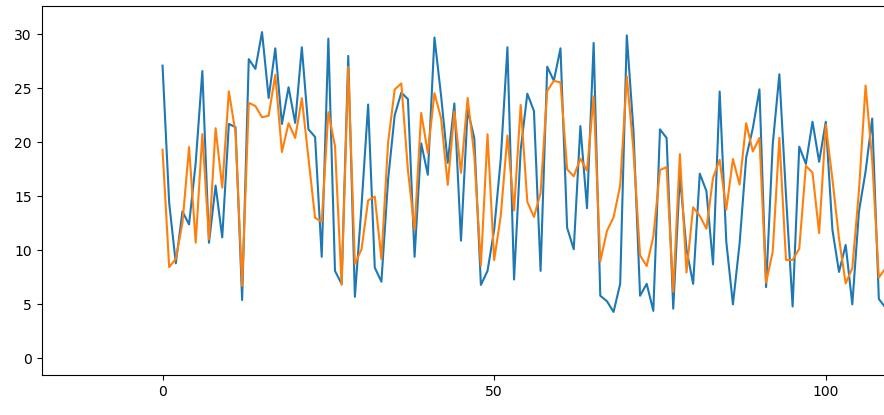
青が実際の気温でオレンジが予測した気温です。
おおおおー、バシッと予測できるとは思っていませんでしたが、そこそこ近い値なのではないでしょうか。
この予測と実気温の差分の標準偏差を求めると4.2℃でしたので、実気温から大体±4.2くらいの範囲で予測できていると言うことでしょうか。当たり前ですが気温の要素を使わずにこのくらいの精度ですから、まあまあすごいと私は感じました。
つまり気温以外の要素と気温にはなんらかの相関があって、その相関をモデルにうまく落とし込んでいるということだと思います。面白いですね!
必要要素を少なくする
ただ、このモデルには5要素を用いていますが、実際使うことを考えると必要な要素は少なければ少ないほど良いですよね!
例えば今回だと降雨量と湿度はお互いに相関がありそうです。すると予測するにあたってはこの2つのうちどちらかだけでも良いということになります。
ただし、少なすぎてもうまく予測できません。下図は極端な例ですが、降雨量のみで予測してみた結果です。
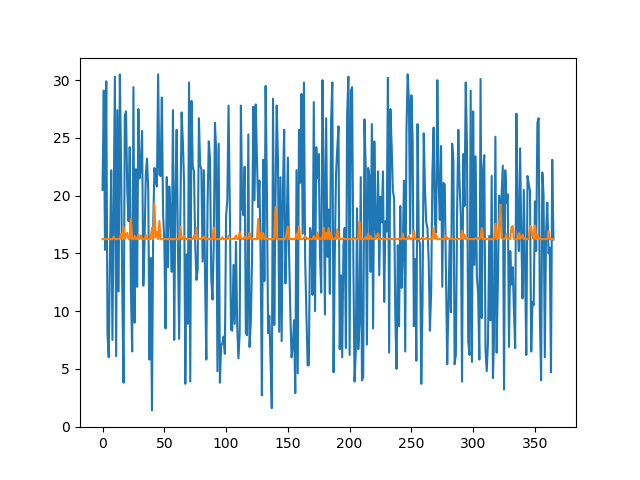
当たり前ですが、うまく予測できていませんね。
こんな感じで“必要”な要素を少なくすることをやってみました。やり方は試行錯誤で実施しました。組み合わせを変えて精度を比較しながら少ない要素で精度が高くなる組み合わせを抽出しました。
精度と組み合わせの結果を以下に示します。
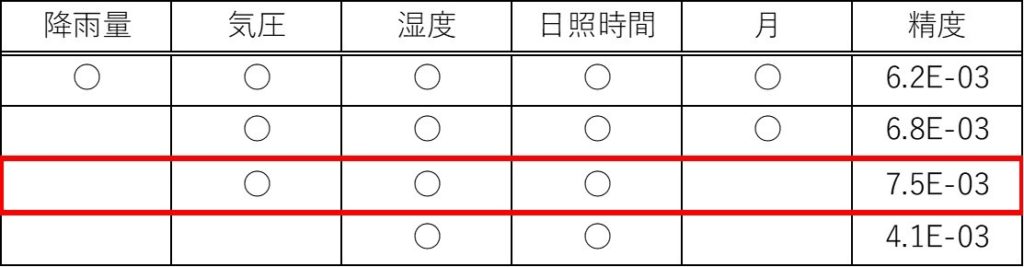
試した中では気圧、湿度、日照時間の3つを使ったものが最も精度が良かったです。要素が少ない方が精度が良いというのも驚きました。多すぎても必要でない特徴が抽出されて精度が悪くなるのでしょうか。
なにはともあれ今回は、この3要素で気温をそれなりに予測?ができることがわかりました。
入力した要素から予測してみよう!
一応目的であった気温の予測ができることがわかったので、このまま終わっても良かったのですが、せっかくなのでもう少し使い勝手良くしたいと思います。
具体的にはこちらが入力した3要素に対して気温を返してくれるようにします。
作成したコードを以下に示します。実は前述のコードの最終行で作成したモデルを他で使えるように保存していましたので、それを読み込んで使います。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 |
# encoding: utf-8 import keras import numpy as np import pandas as pd from sklearn import preprocessing from sklearn.model_selection import train_test_split from keras.models import Sequential, model_from_json from keras.layers.core import Dense from keras.optimizers import RMSprop import matplotlib.pyplot as plt #学習したモデルの読み込み model = keras.models.load_model('and.h5') #入力パラメータを格納する変数の設定 a1 = np.zeros(5) #変数へ入力するパラメータの格納 a1[0] = input('平均現地気圧(hPa)>>') a1[1] = input('平均湿度(%)>>') a1[2] = input('日照時間(時間)>>') #入力したパラメータの出力 print('平均現地気圧=',a1[1],'(hPa)','平均湿度=',a1[2],'(%)','日照時間=',a1[3],'(時間)') #各パラメータの正規化!改善の余地あり! X_test = np.c_[(a1[0]-983.1)/48, (a1[1]-19)/81, a1[2]/13.6] #モデルを使った予測 y_ = model.predict(X_test) #結果の出力 print('予測気温=',y_[0,0],'(℃)') |
1番苦労したのはパラメータの正規化のところですね。
もともとのモデルで正規化しているのを忘れていて、そのままパラメータをモデルに入力して結果、予測気温が-2℃となったので、おかしいなーと思っていたのですが、原因を見つけるのに苦労しました。
原因はわかったのですが、うまく正規化する方法がわからず、こちらのコードではベタ打ちで正規化する結果となっています😫。
色々ありましたが、実際にこのプログラムを実行した結果がこちら

ちゃんと入力した値に対して予測した気温が返ってきました!
これで気温が気になっても気圧と湿度と日照時間がわかれば予測できますね(3つを知るほうが難しいことは内緒です。あと東京以外でも同じ予測ができるかはわかりません。)!
まとめ
今回はPythonを使って機械学習をしてみました。
ん~一応できたはできましたけど使いこなすにはまだまだ修行が足りないですね。
あとせっかく作ったコードですが、実際にサーバにアップしてWEBアプリとして実行してみたいというのもあります。しかし今のところその方法がわかりません。やっぱりレンタルサーバでなく自由度の高いVPSサーバを使うしかないのでしょうか。
TensorFlowはAndroidで動くTensorFlowLiteというものもあるみたいですのでそちらにも挑戦してみたいと思います。


コメント