
前回の記事でGoogleMapの検索結果をスクレイピングする方法について紹介しましたが、その方法でがうまくスクレイピングできないことがわかりました(ご指摘いただきましたありがとうございます。)。

おそらくGoogleMapの仕様が変わってしまったからだと思います。classの名前やidの名前が全く違うものになっていました。以前にも確認したことがあったのですが、定期的に変わるようです。
なので、修正した方法も今後使えなくなる可能性が大きいです。そこで変更の可能性があるところだけ皆さんで修正してもらえれば使える内容にしようと思いますので、ご興味ある方は見てもらえれば幸いです。なお、スクレイピングの基本的なところは以前の記事を参考にしていただければと思います。
![]()
方針

紹介する方法の大まかな方針ですが、前回とほぼ変わっていませんが、以下のとおりです。
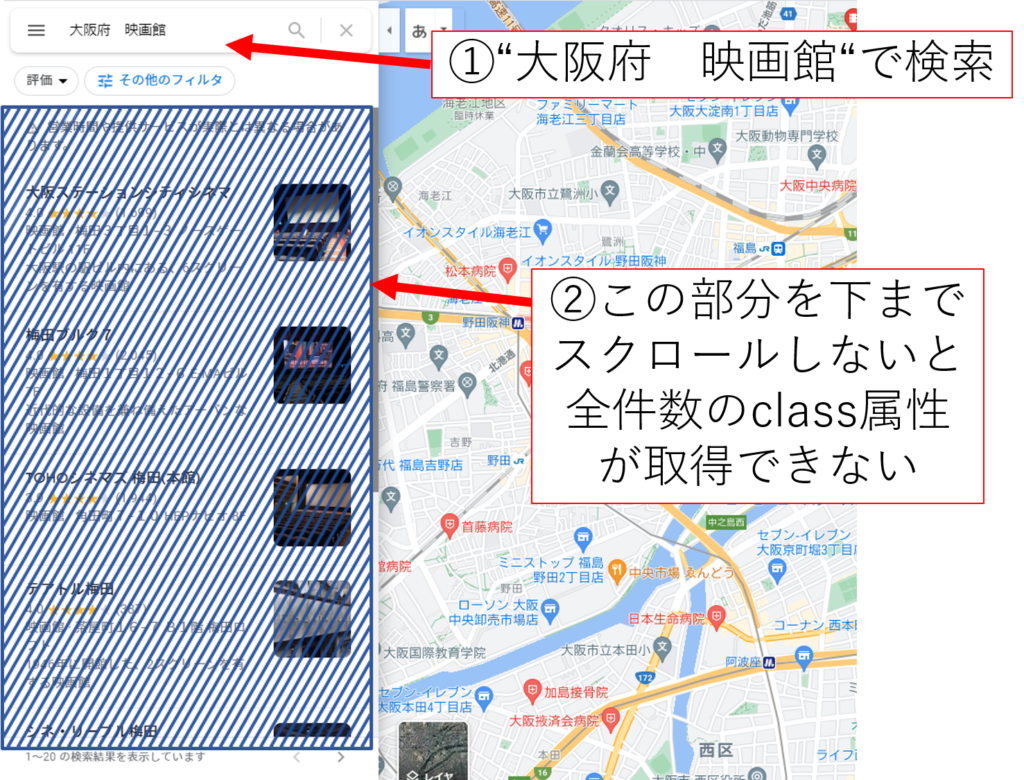
①GoogleMapを開き検索
↓
②検索結果を下までスクロールし全URLを取得(1ページおそらく20件)
↓
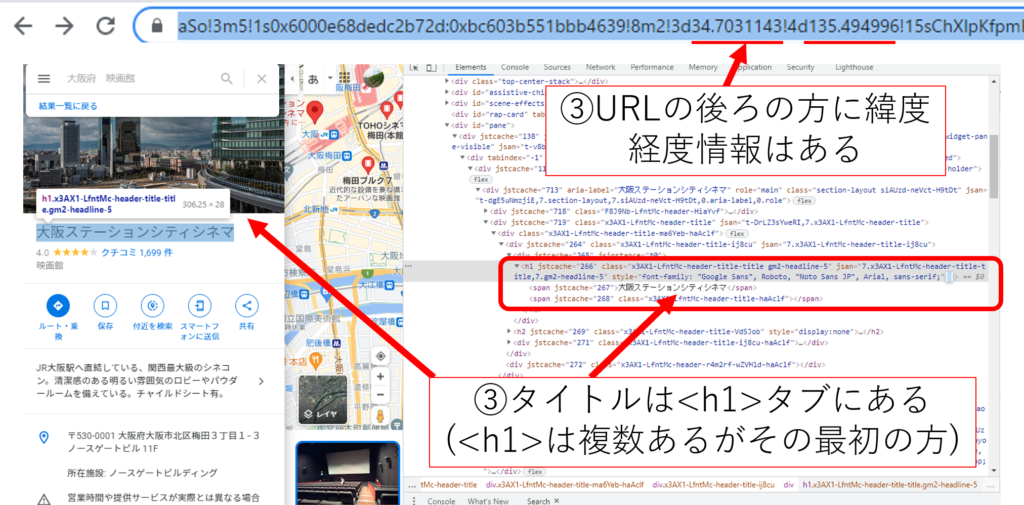
③タブを開き取得したURLを一つ一つ開き、緯度経度を取得
↓
④全URLを調べ終えたら一旦タブを閉じ、次の検索ページに移動
↓
以下、全検索結果終了まで同じ

コードの解説
作成したコードの全文をまず載せます。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 |
import time from selenium import webdriver #driverのオプションを作成 options = webdriver.ChromeOptions() #エラー表示がなくなる(次の行をコメントアウトすると画面が表示される) #options.add_experimental_option('excludeSwitches', ['enable-logging']) # ヘッドレスモードを有効にする(次の行をコメントアウトすると画面が表示される)。 #options.add_argument('--headless') # ChromeのWebDriverオブジェクトを作成する。 driver = webdriver.Chrome(executable_path=r"C:\chromedriver_win32\chromedriver.exe", options=options) #タイトル格納リスト title = [] #緯度格納リスト ido = [] #経度格納リスト keido = [] #検索する語句 name = '大阪府 映画館' #ranking関数 def ranking(driver): # ループ番号、ページ番号を定義 i = 1 # 最大何ページまで分析するかを定義 i_max = 200 # 現在のページが指定した最大分析ページを超えるまでループする while i <= i_max: ###############ここはスクロールバーをスクロールする部分 #フラグの定義 flag = True #スタート時間の取得 start = time.time() #スクロール対象のクラスを定義(変化あり)!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!! scroll_class = 'section-layout section-scrollbox cYB2Ge-oHo7ed cYB2Ge-ti6hGc siAUzd-neVct-Q3DXx-BvBYQ' #フラグがTrueの場合続く while flag == True: #スタートから15秒経つと強制的にスクロール終了 if time.time() - start < 15: #JavaScriptメソッドで、要素を指定しつつスクロール処理 #scrollTopを取得 startHeight = driver.execute_script("var startHeight = document.getElementsByClassName('"+scroll_class+"')[1].scrollTop; return startHeight") #scrollHeightを取得 lastHeight = driver.execute_script("var lastHeight = document.getElementsByClassName('"+scroll_class+"')[1].scrollHeight; return lastHeight") #offsetHeightを取得 offsetHeight = driver.execute_script("var offsetHeight = document.getElementsByClassName('"+scroll_class+"')[1].offsetHeight; return offsetHeight") #スクロール量を増やす driver.execute_script("document.getElementsByClassName('"+scroll_class+"')[1].scrollTop +=3000;")# document.getElementsByClassName('section-layout section-scrollbox scrollable-y scrollable-show section-layout-flex-vertical')[1].scrollHeight;") #スクロールが下まで行くとフラグをFalseにしてループ終了 if startHeight == lastHeight-offsetHeight: flag = False else: flag = True #ループが続く場合は3秒待ってから time.sleep(3) else: #15秒で強制終了した場合 print("scrolltimeup") break ###############ここからスクレイピング #検索結果の取得(変化あり)!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!! class_group = driver.find_elements_by_css_selector('.a4gq8e-aVTXAb-haAclf-jRmmHf-hSRGPd') #検索結果のURLを格納するリスト urls=[] #検索結果のURLを格納するリスト for elemnum in class_group: #検索結果のURL(hrefタグ)を抽出してurlsに格納 urls.append(elemnum.get_attribute("href")) # タイトルとリンクを抽出しリストに追加するforループ #新しいタブを作る(抽出結果をひとつひとつここで開く) driver.execute_script("window.open()") #新しいタブに移動する driver.switch_to.window(driver.window_handles[1]) #URLを一つ一つ表示する for elemnum in urls: #URLに移動する driver.get(elemnum) #3秒間待機 time.sleep(3) #<h1>要素の最初を取得(elementsでなくelementとすることで最初のtagを取得) elele = driver.find_element_by_tag_name('h1') #タイトル print(elele.text) #タイトル追加 title.append(elele.text) #現在のurl取得 txt = driver.current_url #txtの中の'!3d'の位置を特定 pos = txt.find('!3d') #txtの'!3d'の位置以降を抽出 txt2 = txt[pos+3:] #txt2を'!4d'で分割(txt3[0]が緯度) txt3 = txt2.split('!4d') #txt3の後ろの10桁を取得(txt4が経度) tex4 = txt3[1][:10] print(txt3[0]) print(tex4) #緯度を追加 ido.append(txt3[0]) #経度を追加 keido.append(tex4) #ループ後ウインドウを閉じる driver.close() #もとのタブに戻る driver.switch_to.window(driver.window_handles[0]) #次ページのボタンが無かったら終わり try: #次ページのidをクリック(変化あり)!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!! driver.find_element_by_id('ppdPk-Ej1Yeb-LgbsSe-tJiF1e').click() # iを更新 i = i + 1 # 3秒間待機 time.sleep(5) except: #ループを終わらせるためにiをi_max以上にする i = i_max + 1 #終わり print('スクレイピング終了') return ############### #指定したURLに移動する driver.get('https://www.google.co.jp/maps?hl=ja&tab=rl&authuser=0') # HTML内で検索ボックス(name='q')を指定する search = driver.find_element_by_name('q') # 検索ワードを送信する search.send_keys(name) # 検索ボタンをクリック driver.find_element_by_id("searchbox-searchbutton").click() # 3秒間待機 time.sleep(8) # ranking関数を実行してタイトルとURLリストを取得する ranking(driver) # タイトルリストをテキストに保存 with open('title.txt', mode='w', newline="", encoding='utf-8') as f: f.writelines("\n".join(title)) # 緯度経度をテキストに保存 with open('ido.txt', mode='w', newline="", encoding='utf-8') as f: f.writelines("\n".join(ido)) with open('keido.txt', mode='w', newline="", encoding='utf-8') as f: f.writelines("\n".join(keido)) # ブラウザを閉じる driver.quit() |
コードの細かい説明はコメント分で書いてあるので参考にしていただければ幸いです。
工夫した点について解説します。
画面のスクロール
検索した画面には検索結果がずらっと表示されます。その一つ一つを取得したいのですが、そのままでは取得できません。画面をスクロールして検索結果をロードしないといけないみたいです。そのための部分です。画面をスクロールするにはpythonの中でjavascriptを使ってhtmlを操作するのがいいみたいです。こちらのサイトを参考にしました。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
#scrollTopを取得 startHeight = driver.execute_script("var startHeight = document.getElementsByClassName('"+scroll_class+"')[1].scrollTop; return startHeight") #scrollHeightを取得 lastHeight = driver.execute_script("var lastHeight = document.getElementsByClassName('"+scroll_class+"')[1].scrollHeight; return lastHeight") #offsetHeightを取得 offsetHeight = driver.execute_script("var offsetHeight = document.getElementsByClassName('"+scroll_class+"')[1].offsetHeight; return offsetHeight") #スクロール量を増やす driver.execute_script("document.getElementsByClassName('"+scroll_class+"')[1].scrollTop +=3000;")# document.getElementsByClassName('section-layout section-scrollbox scrollable-y scrollable-show section-layout-flex-vertical')[1].scrollHeight;") #スクロールが下まで行くとフラグをFalseにしてループ終了 if startHeight == lastHeight-offsetHeight: flag = False else: flag = True |
しかしそのままでは、なぜかうまくいきませんでしたので、こちらのサイトを参考に”スクロールトップ=スクロール高さ-スクロールオフセット“となったとき下までスクロールしたとみなして、終了しました。
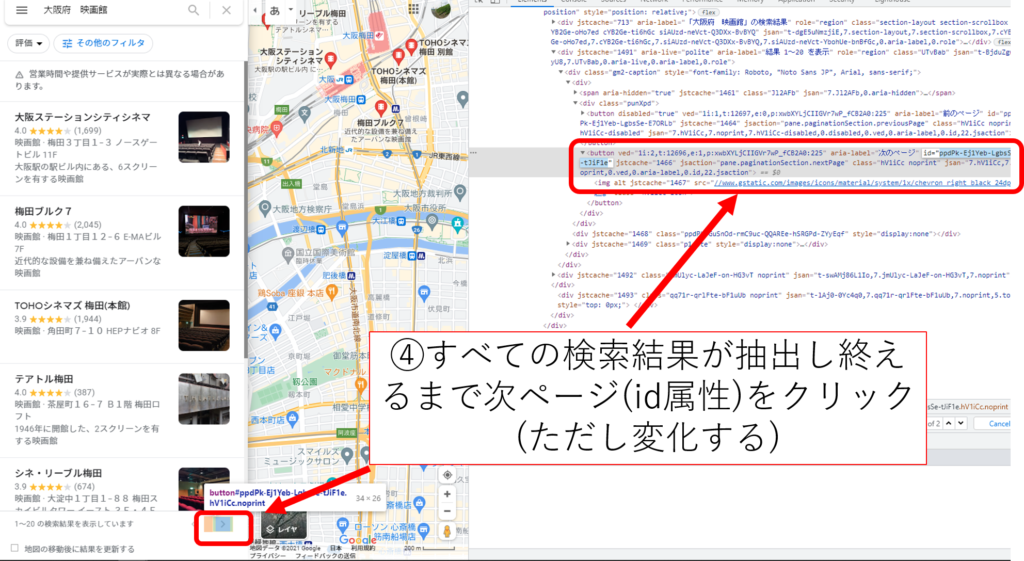
変更する箇所
今後変更が予想される場所が3箇所あります。
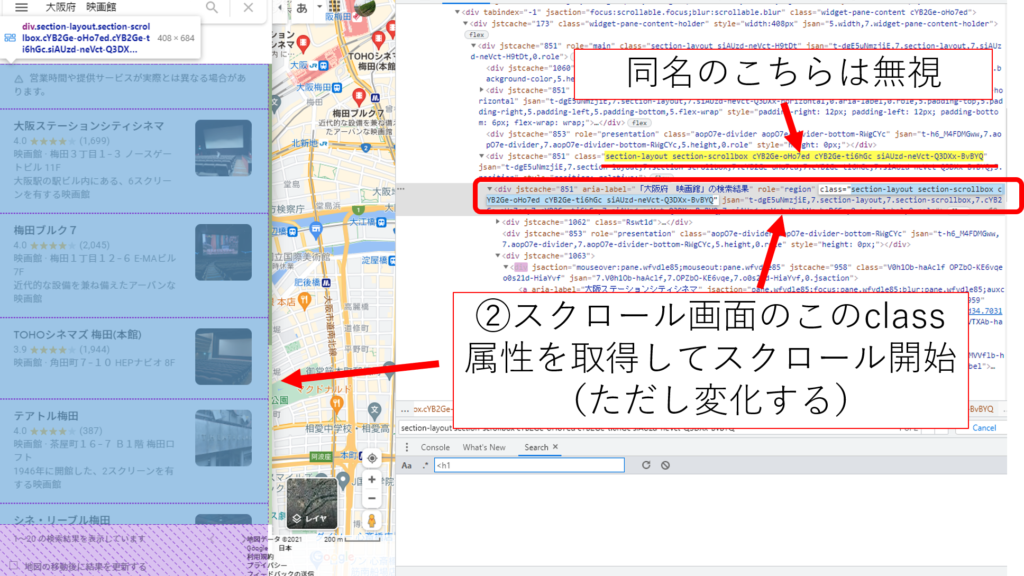
スクロール対象のクラス
|
1 2 |
#スクロール対象のクラスを定義(変化あり)!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!! scroll_class = 'section-layout section-scrollbox cYB2Ge-oHo7ed cYB2Ge-ti6hGc siAUzd-neVct-Q3DXx-BvBYQ' |
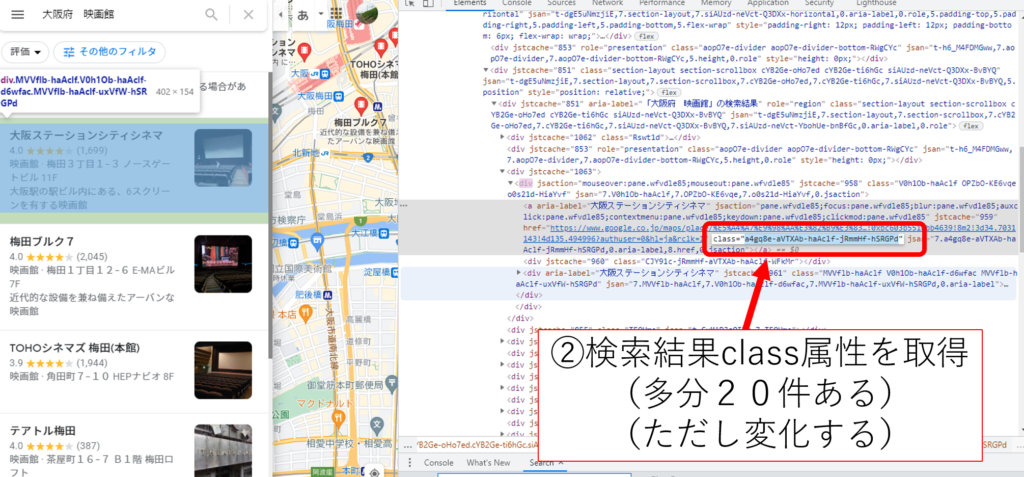
検索結果のクラス
|
1 2 |
#検索結果の取得(変化あり)!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!! class_group = driver.find_elements_by_css_selector('.a4gq8e-aVTXAb-haAclf-jRmmHf-hSRGPd') |
次ページのクラス
|
1 2 |
#次ページのidをクリック(変化あり)!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!! driver.find_element_by_id('ppdPk-Ej1Yeb-LgbsSe-tJiF1e').click() |
以上になります。タイトル以外にも検索結果の電話番号やサイトURLなんかを取得したい場合には別途classやidの取得が必要になり、それも変更する可能性があります。
![]()
まとめ
今回前回の記事でできなくなったスクレイピングの修正を行いました。ただ、今後のことを考えるとGoogleMapAPIを使って何かしらするのが良いかもしれないです。勉強したらまた紹介したいと思います。


コメント
あしかぺんぎん様
ご対応大変ありがとうございました。
しかも、こんなに早く詳しくすごいですねぇ~
早速試してみます。
また、修正のコツまで記載いただいたのでしっかり勉強してみます。